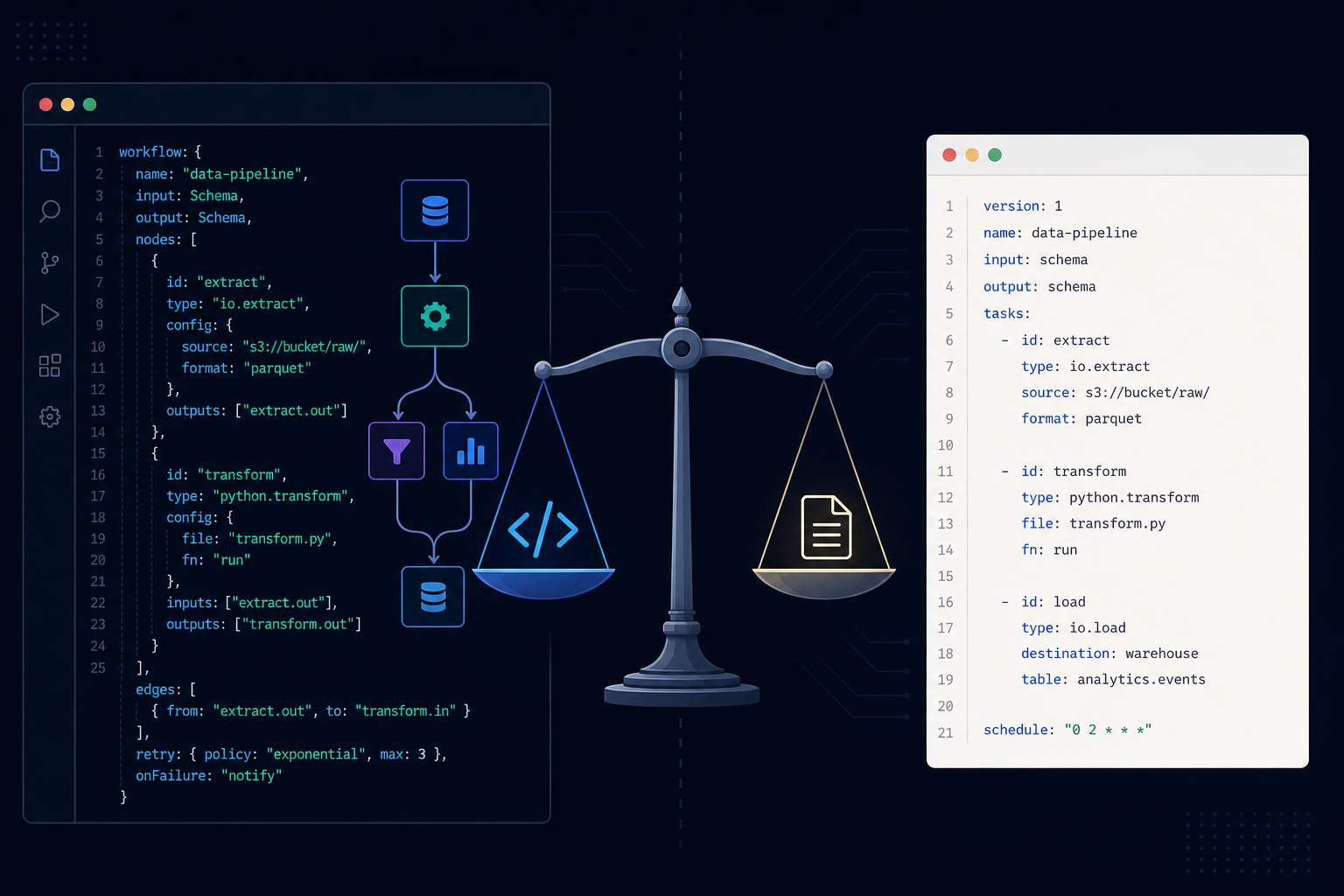
Workflow as Code vs. Workflow as Config: What the Trade-off Actually Is
Every AI workflow platform eventually forces this decision: do you define workflows in code (a Python function, a Go struct, a TypeScript object) or in configuration (YAML, JSON, a visual graph editor)?
This is not a taste question. The two approaches have genuinely different trade-off profiles, and the wrong choice for your context will cost you.
What "workflow as config" means in practice
Configuration-based workflows describe the workflow graph as data — a YAML file, a JSON document, or a visual canvas that serializes to one. The workflow engine reads the config, constructs the execution graph, and runs it.
The appeal is broad accessibility: non-engineers can read and sometimes write workflow definitions. Diffs are visible in pull requests. Serialized graphs can be stored, versioned, and loaded at runtime without a deployment.
The cost is expressiveness. Config-based workflows handle the common case — a linear sequence of steps, maybe a branch or a loop — but struggle with dynamic behavior. When you need to construct part of the graph based on runtime data, spawn variable numbers of sub-tasks based on an LLM decision, or share complex logic across workflow types, you are fighting the config format rather than using it.
What "workflow as code" means in practice
Code-based workflows define the execution graph in a programming language — either as an explicit graph construction or as an annotated function that the runtime instruments.
The appeal is full expressiveness: anything the language can express, the workflow can do. Shared libraries work. Type checking works. Unit tests work. Complex dynamic behavior is first-class, not a workaround.
The cost is that only engineers write workflows. There is no drag-and-drop canvas. Non-technical stakeholders cannot inspect or modify workflow definitions without code changes.
The false middle: visual-first tools
Many platforms offer a visual canvas that generates config under the hood. This sounds like the best of both worlds. In practice it is often the worst: the canvas constrains what is expressible, and the generated config is not something a reasonable human would write or maintain directly.
When the workflow outgrows what the canvas can represent — which happens quickly in production AI systems — teams are stuck maintaining machine-generated config that is hard to read, diff, or refactor.
The right framework for the decision
The key question is not "do we want code or config?" It is: who needs to own workflow logic, and how often does it change?
If workflow logic changes frequently and requires engineering work anyway (new LLM steps, new tool integrations, new branching logic), code wins. The flexibility pays for itself and the "non-engineers can edit it" promise was never going to materialize.
If workflow definitions are stable, standardized, and need to be created by operations or product teams without engineering involvement — a rule engine for routing, a templated set of fixed steps — config can work. But be honest about how stable "stable" actually is.
Version control is the common requirement
Regardless of format, workflow definitions need to be version-controlled, diffable, and reviewed before deployment. A workflow that changes in production without a corresponding code or config change is an audit and debugging problem.
This requirement — workflow definitions as versioned artifacts — is easier to satisfy with code than with config stored in a database, which is how many visual workflow tools end up storing their definitions.
AgentRuntime defines workflows as code with an explicit graph schema, giving engineers full expressiveness while maintaining the structured, versionable artifact that production operations require. Join the waitlist for early access.